What it is
Knowledge stored as atoms
smrti is an AtomSpace-inspired graph database for agent memory. Each node—an atom—carries a Bayesian truth value, an emotional valence, and an attention weight. Retrieval ranks by computed salience across five dimensions, not by timestamp. Your agent remembers what matters, not just what happened last.
Evidence is append-only. Truth values are never mutated directly—observations are logged and merged during consolidation epochs via PLN (Probabilistic Logic Networks). Multi-tenant isolation keeps agent memories separate by tenant and space.
Architecture
Six layers, one SQLite file
Vector indexing via sqlite-vec (multilingual-MiniLM-L12-v2, 384 dimensions, 50+ languages). Entity resolution cascades through exact match, cross-type label match, alias lookup, fuzzy matching (RapidFuzz), and embedding similarity before creating new nodes.
API
Six operations
remember, recall, believe, reflect, forget, personality. The Python API is the same interface the MCP and REST servers expose.
from smrti import Smrti engine = Smrti(personality="deterministic") # Store a memory with negative valence engine.remember( "Deploying on Friday caused a 2-hour outage", valence=-0.8 ) # Positive experience engine.remember( "Feature flags made the rollout safe", valence=0.6 )
# Salience-ranked retrieval results = engine.recall("deployment risks") for r in results: print( f"{r.atom.content}", f"salience={r.salience:.2f}", f"confidence={r.atom.truth.confidence:.2f}", f"valence={r.atom.valence.valence:.1f}", ) # KNN search → 1-hop graph expansion → salience scoring # Negative-valence atoms surface first when relevant
# Assert a belief with supporting evidence engine.believe( "Feature flags reduce deployment risk", probability=0.85, evidence="3 successful staged rollouts" ) # Evidence is appended, not overwritten. # Conflicting observations create contradiction links. # The consolidation epoch merges via PLN.
# Run a consolidation epoch epoch = engine.reflect() print(epoch) # EpochResult( # beliefs_updated=3, # atoms_decayed=12, # atoms_pruned=1, # lti_promoted=2, # new_connections=4, # contradictions_resolved=1 # ) # Process evidence → decay STI/LTI → promote high-LTI # → resolve contradictions → prune low-salience atoms
# Soft-forget: recall matching atoms, decay confidence targets = engine.recall("Friday deployment outage", top_k=5) for r in targets: engine.db.execute( "UPDATE atoms SET confidence = confidence * 0.3 WHERE id = ?", (r.atom.id,) ) # No hard delete — the consolidation epoch # prunes when salience drops low enough
# Switch preset at runtime engine.set_personality("analytical") # 6 presets: balanced, analytical, curious, # empathetic, maverick, deterministic # Each tunes 16 hyperparameters that control # learning rate, decay, promotion, and salience weights
Retrieval
Salience scoring
Every recall computes a weighted sum across five dimensions. Personality hyperparameters control the weights.
Dynamic weight shifting
When valence drops below −0.5, weight shifts from STI to valence. Severe negative-valence atoms (errors, failures) get an LTI floor of 0.5 on creation, preventing epoch pruning. Critical errors outrank recent trivia.
Severity classification
Each recall result carries a severity tag. The proxy injects memories as plain imperative instructions into the system prompt: YOU MUST NOT, AVOID, or Note:
- critical_warning — valence < −0.5, intensity > 0.5
- known_antipattern — probability < 0.3, confidence > 0.3
- context — neutral background
Agent Ecosystems
Spaces as social graphs
read_spaces decides who can see whom. Give each agent its own space and personality, then wire them together. Each space consolidates independently, so the same event decays differently for every agent.
Spaces also support set theory operations: space_overlap, space_intersection, space_difference, space_union. Matching uses a three-signal contextual score (embedding + entity-type + graph neighborhood) that correctly separates homonyms like "Java" the language from "Java" the island. When two spaces overlap significantly, space_merge() materialises a bridge space — new atoms with PLN-merged truth values and blended valence, linked back to both parents. Bridge discovery runs automatically every 10th consolidation epoch.
Personality
16 hyperparameters, 6 presets
Each preset tunes how the agent learns, forgets, and weighs emotion. Swap at runtime with set_personality() or define custom profiles.
Serve
Four modes, same engine
All server modes run automatic entity extraction after every remember() call — building concept nodes and relation edges from stored episodes via LLM. Disable with SMRTI_EXTRACT=0.
YOU MUST NOT, AVOID, Note:) into the system prompt.Visualizer
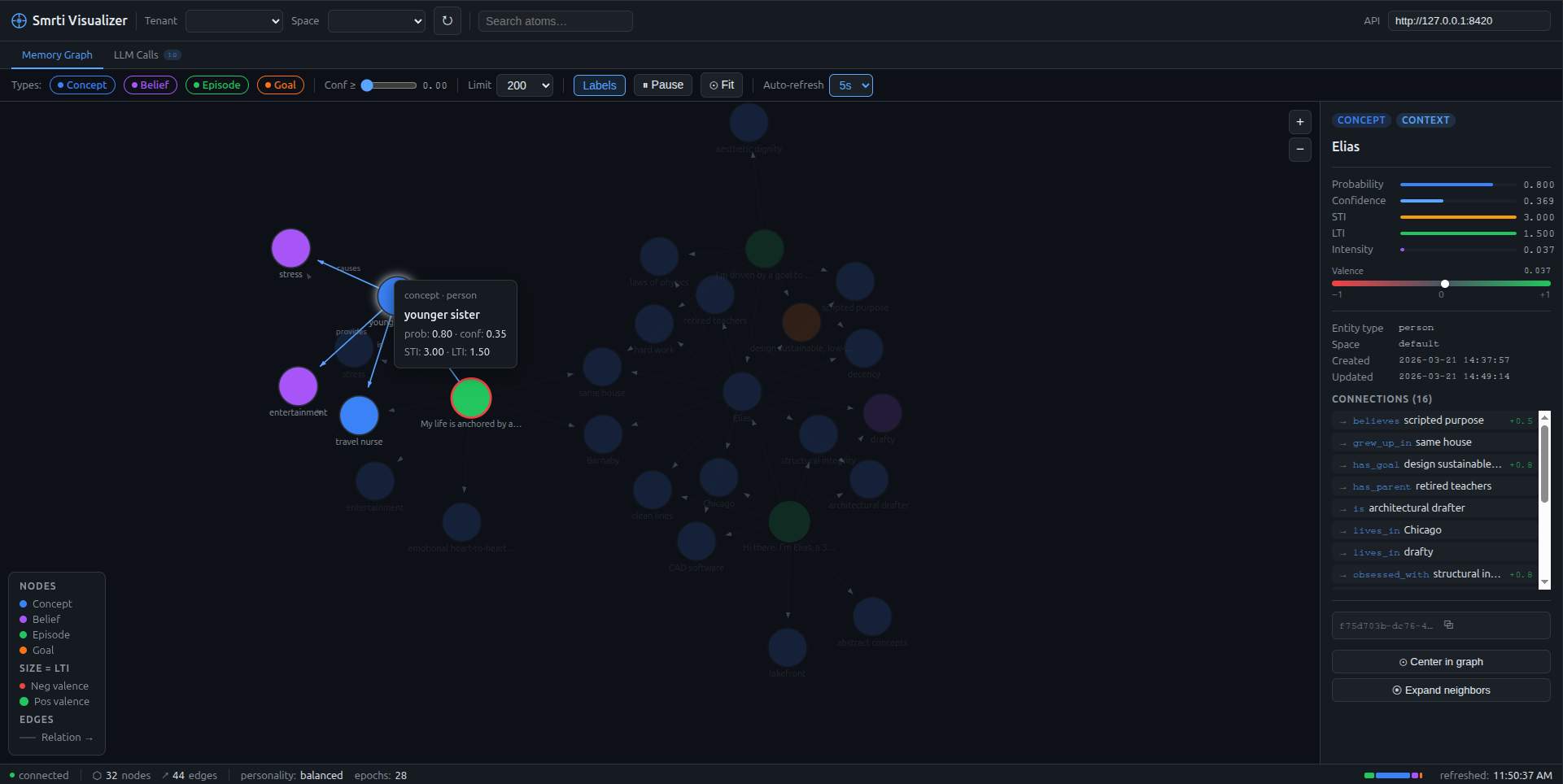
Concept nodes (blue) linked to episodes (green) via typed edges. Node size encodes LTI. Valence-tinted stroke. Inspector panel shows full atom stats on click.